Apache DolphinScheduler
Orquestador de datos distribuido
Gratis
Plataformas soportadas
web
Etiquetas de herramienta
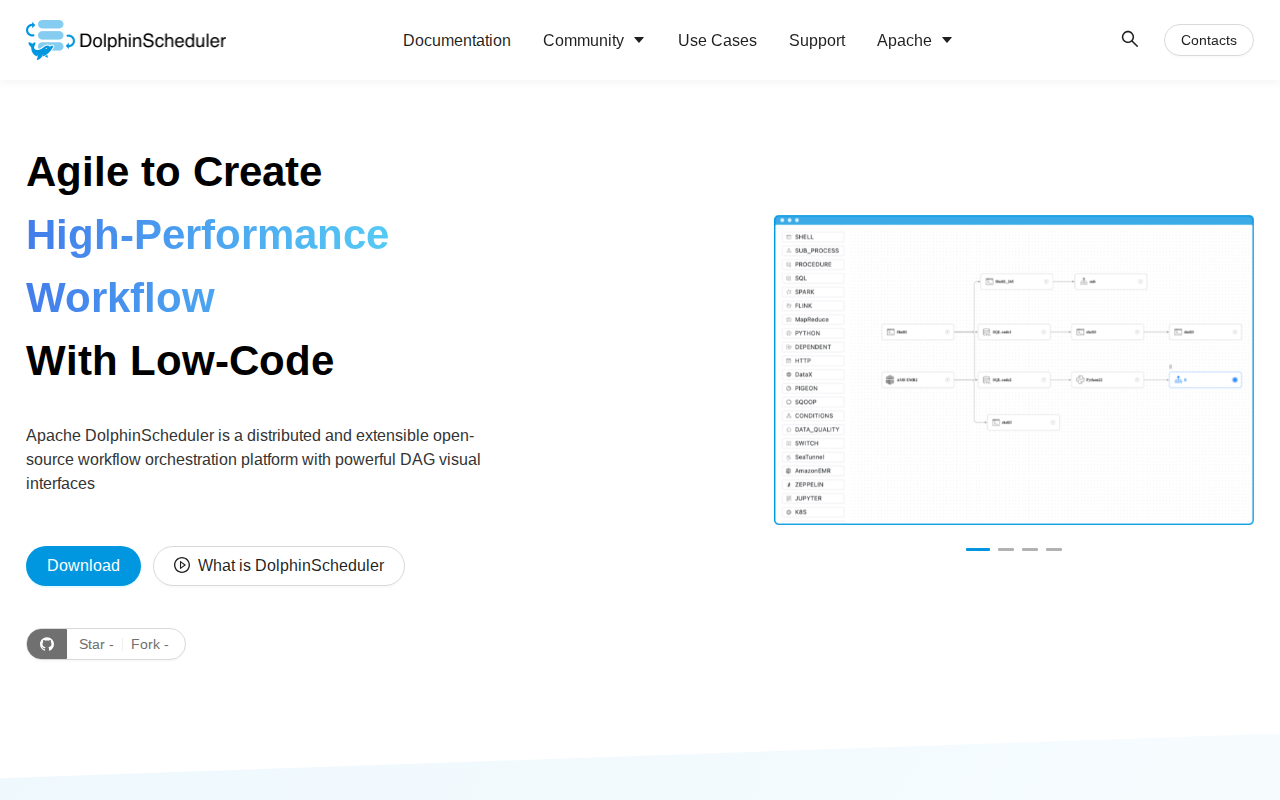
Qué es Apache DolphinScheduler
Apache DolphinScheduler es una plataforma de orquestación de flujos de trabajo distribuida y nativa de la nube, diseñada para la gestión de pipelines de datos de alto rendimiento. A diferencia de los programadores tradicionales como Airflow, cuenta con un editor visual de DAG (Grafo Acíclico Dirigido) y una arquitectura multi-master/multi-worker que elimina los puntos únicos de fallo. Admite dependencias de tareas complejas, multi-tenancy y alta disponibilidad, lo que lo hace ideal para equipos de ingeniería de datos a gran escala. Al desacoplar el programador del motor de ejecución, proporciona una tolerancia a fallos robusta y monitoreo en tiempo real para miles de tareas de datos concurrentes en entornos heterogéneos.
Funciones principales de Apache DolphinScheduler
Diseño visual de flujos DAG
La interfaz intuitiva de arrastrar y soltar permite a los ingenieros construir pipelines de datos complejos sin escribir código para la lógica de orquestación. Al mapear visualmente las dependencias de las tareas, los usuarios pueden gestionar fácilmente ramificaciones, ejecución paralela y lógica condicional. Esto reduce el tiempo dedicado al mantenimiento del pipeline y hace que la estructura del flujo de trabajo sea transparente para los interesados no técnicos, reduciendo significativamente la barrera de entrada en comparación con las herramientas de configuración basadas solo en código.
Arquitectura Multi-Master/Multi-Worker
DolphinScheduler emplea una arquitectura descentralizada donde múltiples nodos maestros y trabajadores operan en un clúster. Este diseño garantiza una alta disponibilidad; si un nodo maestro falla, otros asumen automáticamente la carga de trabajo. Esto proporciona una escalabilidad superior en comparación con los sistemas de un solo programador, permitiendo que la plataforma maneje decenas de miles de tareas concurrentes sin degradación del rendimiento ni tiempo de inactividad, algo crítico para la infraestructura de datos de nivel empresarial.
Soporte robusto de Multi-Tenancy
La plataforma proporciona un aislamiento estricto de recursos a través de multi-tenancy, permitiendo que diferentes departamentos o equipos compartan el mismo clúster de forma segura. Al asignar tareas a usuarios específicos de Linux y colas de recursos, DolphinScheduler asegura que el trabajo intensivo de un equipo no agote los recursos de otros. Esto es esencial para grandes organizaciones donde los equipos de ingeniería de datos deben equilibrar los costos de infraestructura compartida con estrictos SLA de rendimiento para unidades de negocio individuales.
Amplio soporte de tipos de tareas
Soporte nativo para una amplia gama de tipos de tareas, incluyendo Shell, Python, Spark, Flink, MapReduce, DataX y SQL. Esta versatilidad permite a los equipos orquestar trabajos de procesamiento de datos heterogéneos dentro de una sola plataforma. Al proporcionar plugins estandarizados para estos motores, se simplifica la integración de diversas tecnologías de big data, reduciendo la necesidad de código de integración personalizado y simplificando la arquitectura general del stack de datos.
Monitoreo y alertas en tiempo real
El monitoreo integrado proporciona visibilidad granular sobre la ejecución de tareas, incluyendo el uso de CPU/memoria y registros. El sistema admite alertas personalizables vía email, Slack, DingTalk y WeChat. Cuando una tarea falla o excede un umbral de duración, se activan alertas automáticas, permitiendo a los ingenieros responder de inmediato. Este monitoreo proactivo reduce el Tiempo Medio de Recuperación (MTTR) y garantiza la fiabilidad de los pipelines de datos críticos en entornos de producción.
Cómo usar Apache DolphinScheduler
- Despliegue el clúster de DolphinScheduler usando Docker Compose o Kubernetes mediante el Helm chart oficial., 2. Acceda a la interfaz web en el puerto 12345 y configure sus conexiones a fuentes de datos (ej. MySQL, PostgreSQL, Hive) en la pestaña 'Security'., 3. Cree un proyecto y use el editor DAG de arrastrar y soltar para definir nodos de tareas, incluyendo scripts de Shell, Python, Spark, Flink o SQL., 4. Defina dependencias de tareas y parámetros de ejecución, como políticas de reintento, límites de tiempo y asignaciones de grupos de recursos., 5. Configure disparadores de programación usando expresiones Cron o dependencias basadas en eventos para automatizar la ejecución del pipeline., 6. Monitoree el estado de las tareas en tiempo real, registros y uso de recursos a través del panel 'Monitor' para asegurar la salud del pipeline.
Casos de uso de Apache DolphinScheduler
Automatización de pipelines ETL
Los ingenieros de datos utilizan DolphinScheduler para automatizar trabajos ETL diarios que extraen datos de bases de datos operativas, los transforman usando Spark y los cargan en un data warehouse. Garantiza la consistencia de los datos mediante la gestión de dependencias y reintentos automáticos.
Gestión de clústeres de Big Data
Los equipos de plataforma gestionan clústeres masivos de Flink y Spark delegando la programación de trabajos a DolphinScheduler. Optimiza la asignación de recursos en todo el clúster, asegurando que los trabajos de análisis de alta prioridad reciban la potencia de cómputo necesaria durante las horas pico.
Integración de flujos de trabajo multiplataforma
Las organizaciones con stacks híbridos lo utilizan para cerrar la brecha entre scripts SQL heredados y modernos pipelines de machine learning basados en Python, proporcionando un plano de control unificado para herramientas de procesamiento de datos dispares.
Quién se beneficia de Apache DolphinScheduler
Ingenieros de Datos
Necesitan una forma fiable y escalable de gestionar pipelines de datos complejos y de múltiples etapas. DolphinScheduler proporciona la potencia de orquestación para automatizar tareas repetitivas y garantizar la calidad de los datos.
Arquitectos de Plataforma
Requieren una solución de alta disponibilidad y multi-tenancy para gestionar infraestructura compartida entre múltiples unidades de negocio, manteniendo un estricto aislamiento de recursos y seguridad.
Ingenieros DevOps
Se enfocan en la estabilidad de la infraestructura y el monitoreo. Se benefician de la arquitectura descentralizada de la plataforma y las capacidades de alerta robustas para mantener el tiempo de actividad de los servicios de datos críticos.
Precios de Apache DolphinScheduler
Software de código abierto bajo la licencia Apache License 2.0. Completamente gratuito para usar, modificar y desplegar en cualquier entorno sin tarifas de licencia.





