Apache DolphinScheduler
Orchestrateur de flux de données
Gratuit
Plateformes supportées
web
Étiquettes d'outil
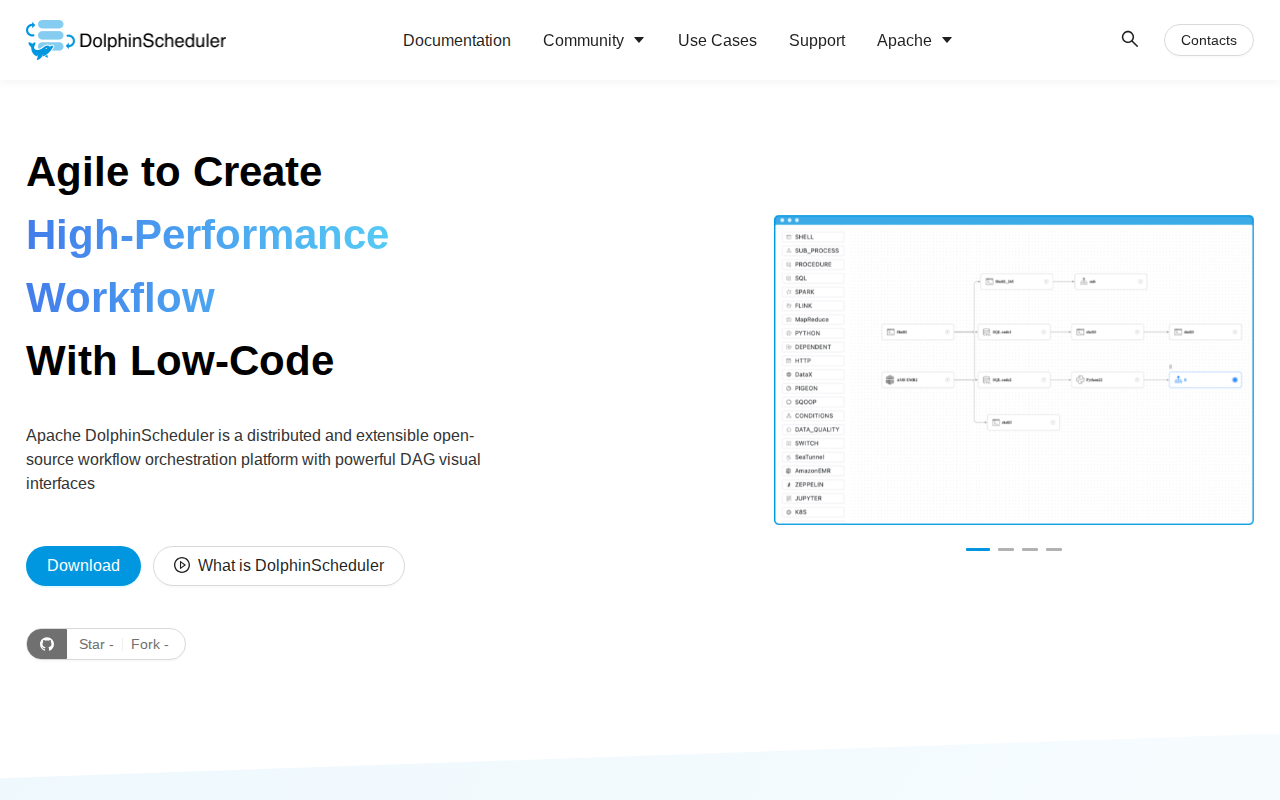
Qu'est-ce que Apache DolphinScheduler
Apache DolphinScheduler est une plateforme d'orchestration de flux de travail distribuée et cloud-native, conçue pour la gestion de pipelines de données haute performance. Contrairement aux ordonnanceurs traditionnels comme Airflow, il propose un éditeur visuel de DAG (Graphe Acyclique Dirigé) et une architecture multi-master/multi-worker éliminant les points de défaillance uniques. Il prend en charge les dépendances de tâches complexes, le multi-tenancy et la haute disponibilité, ce qui le rend idéal pour les équipes d'ingénierie de données à grande échelle. En découplant l'ordonnanceur du moteur d'exécution, il offre une tolérance aux pannes robuste et une surveillance en temps réel pour des milliers de tâches de données simultanées dans des environnements hétérogènes.
Fonctionnalités principales de Apache DolphinScheduler
Conception visuelle de flux DAG
L'interface intuitive par glisser-déposer permet aux ingénieurs de construire des pipelines de données complexes sans écrire de code pour la logique d'orchestration. En cartographiant visuellement les dépendances, les utilisateurs gèrent facilement les branchements, l'exécution parallèle et la logique conditionnelle. Cela réduit le temps de maintenance et rend la structure du flux transparente pour les parties prenantes non techniques, abaissant considérablement la barrière à l'entrée par rapport aux outils basés uniquement sur le code.
Architecture Multi-Master/Multi-Worker
DolphinScheduler utilise une architecture décentralisée où plusieurs nœuds master et worker opèrent dans un cluster. Cette conception garantit une haute disponibilité ; si un nœud master tombe en panne, les autres prennent automatiquement le relais. Cela offre une évolutivité supérieure aux systèmes à ordonnanceur unique, permettant à la plateforme de gérer des dizaines de milliers de tâches simultanées sans dégradation des performances ni interruption, un point critique pour l'infrastructure de données d'entreprise.
Support robuste du multi-tenancy
La plateforme assure une isolation stricte des ressources via le multi-tenancy, permettant à différents départements ou équipes de partager le même cluster en toute sécurité. En mappant les tâches à des utilisateurs Linux et des files d'attente de ressources spécifiques, DolphinScheduler garantit qu'un travail gourmand en ressources d'une équipe ne pénalise pas les autres. C'est essentiel pour les grandes organisations où les équipes d'ingénierie de données doivent équilibrer les coûts d'infrastructure partagée avec des SLA de performance stricts pour chaque unité commerciale.
Support étendu des types de tâches
Support natif d'une large gamme de types de tâches, incluant Shell, Python, Spark, Flink, MapReduce, DataX et SQL. Cette polyvalence permet aux équipes d'orchestrer des travaux de traitement de données hétérogènes au sein d'une plateforme unique. En fournissant des plugins standardisés pour ces moteurs, il simplifie l'intégration de technologies Big Data diverses, réduisant le besoin de code de liaison personnalisé et simplifiant l'architecture globale de la pile de données.
Surveillance et alertes en temps réel
La surveillance intégrée offre une visibilité granulaire sur l'exécution des tâches, incluant l'utilisation CPU/mémoire et les logs. Le système prend en charge des alertes personnalisables via email, Slack, DingTalk et WeChat. Lorsqu'une tâche échoue ou dépasse un seuil de durée, des alertes automatisées sont déclenchées, permettant aux ingénieurs de réagir immédiatement. Cette surveillance proactive réduit le temps moyen de récupération (MTTR) et garantit la fiabilité des pipelines de données critiques en production.
Comment utiliser Apache DolphinScheduler
- Déployez le cluster DolphinScheduler via Docker Compose ou Kubernetes avec le chart Helm officiel., 2. Accédez à l'interface web sur le port 12345 et configurez vos connexions aux sources de données (ex: MySQL, PostgreSQL, Hive) dans l'onglet 'Security'., 3. Créez un projet et utilisez l'éditeur DAG par glisser-déposer pour définir les nœuds de tâches, incluant des scripts Shell, Python, Spark, Flink ou SQL., 4. Définissez les dépendances de tâches et les paramètres d'exécution, tels que les politiques de nouvelle tentative, les limites de temps et les groupes de ressources., 5. Configurez des déclencheurs de planification via des expressions Cron ou des dépendances basées sur des événements pour automatiser l'exécution des pipelines., 6. Surveillez l'état des tâches en temps réel, les logs et l'utilisation des ressources via le tableau de bord 'Monitor' pour assurer la santé des pipelines.
Cas d’utilisation de Apache DolphinScheduler
Automatisation de pipelines ETL
Les ingénieurs de données utilisent DolphinScheduler pour automatiser les tâches ETL quotidiennes qui extraient les données des bases opérationnelles, les transforment via Spark et les chargent dans un entrepôt de données. Il assure la cohérence des données grâce à la gestion des dépendances et aux tentatives automatiques.
Gestion de clusters Big Data
Les équipes plateforme gèrent des clusters Flink et Spark massifs en déléguant la planification des travaux à DolphinScheduler. Il optimise l'allocation des ressources dans le cluster, garantissant que les travaux analytiques prioritaires reçoivent la puissance de calcul nécessaire pendant les heures de pointe.
Intégration de flux multi-plateformes
Les organisations utilisant des piles hybrides l'utilisent pour combler le fossé entre les scripts SQL hérités et les pipelines de machine learning modernes basés sur Python, offrant un plan de contrôle unifié pour des outils de traitement de données disparates.
Qui bénéficie de Apache DolphinScheduler
Ingénieurs de données
Besoin d'un moyen fiable et évolutif pour gérer des pipelines de données complexes à plusieurs étapes. DolphinScheduler fournit la puissance d'orchestration pour automatiser les tâches répétitives et garantir la qualité des données.
Architectes plateforme
Requièrent une solution haute disponibilité et multi-tenant pour gérer l'infrastructure partagée entre plusieurs unités commerciales tout en maintenant une isolation stricte des ressources et la sécurité.
Ingénieurs DevOps
Se concentrent sur la stabilité de l'infrastructure et la surveillance. Ils bénéficient de l'architecture décentralisée de la plateforme et des capacités d'alerte robustes pour maintenir la disponibilité des services de données critiques.
Tarification de Apache DolphinScheduler
Logiciel open-source sous licence Apache 2.0. Entièrement gratuit à utiliser, modifier et déployer dans n'importe quel environnement sans frais de licence.





