結論
ソーシャルメディアモニタリング に最適
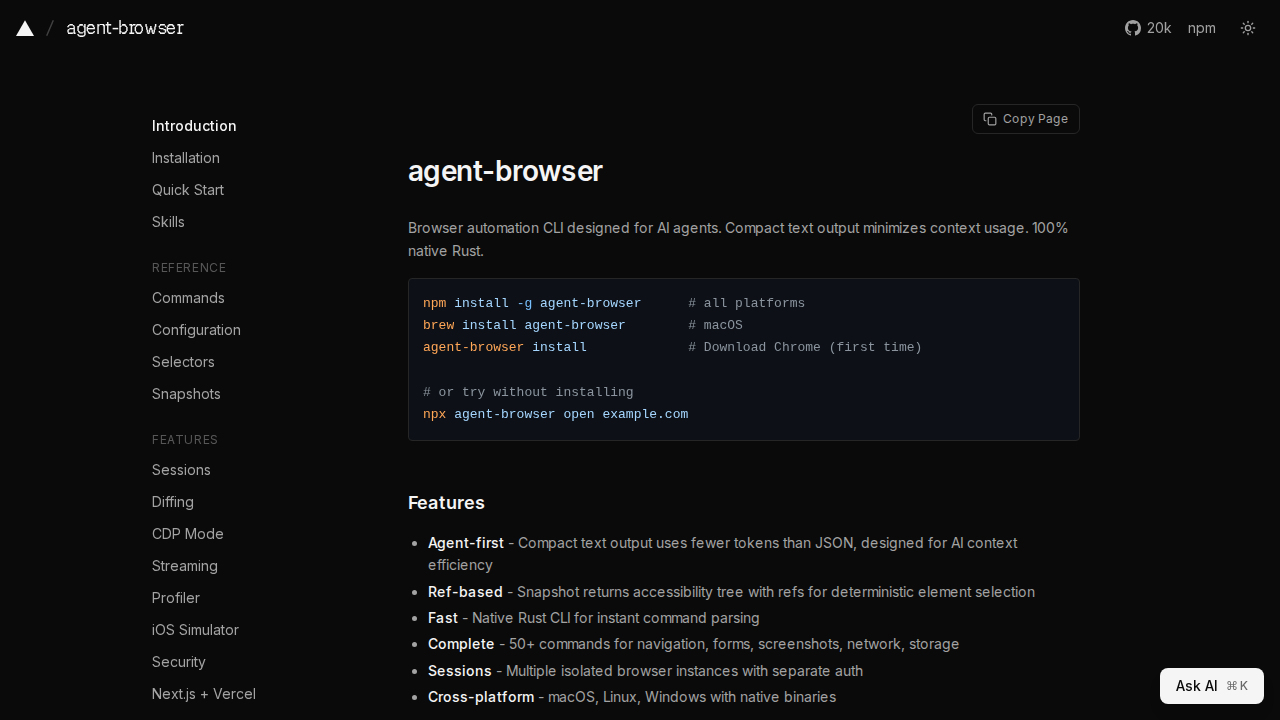
MediaCrawlerは、様々なソーシャルメディアプラットフォームからデータを抽出するために設計された自己メディアクローラーです。キーワードや特定のIDに基づいて投稿やコメントを検索する機能を提供します。複数のプラットフォームとデータベースオプション(SQLiteとMySQL)をサポートしています。Python...
おすすめ対象
研究者
データアナリスト
開発者
主な機能
マルチプラットフォーム対応
キーワードとIDベース検索
データベースオプション
Actions
Share
404 のスクリーンショットとデモ
404 とは
MediaCrawlerは、様々なソーシャルメディアプラットフォームからデータを抽出するために設計された自己メディアクローラーです。キーワードや特定のIDに基づいて投稿やコメントを検索する機能を提供します。複数のプラットフォームとデータベースオプション(SQLiteとMySQL)をサポートしています。Python 3.11とNode.js(一部のプラットフォーム用)が必要です。ユーザーは、コメント抽出やデータベースの選択などの設定を構成できます。ドキュメントには、セットアップ手順、プロジェクトアーキテクチャの詳細、およびトラブルシューティングガイドが含まれています。また、寄付と開発者のサポートオプションも提供しています。このプロジェクトは、依存関係管理にuvを、ブラウザ自動化にPlaywrightを使用しています。
404 の主な機能
マルチプラットフォーム対応
様々なソーシャルメディアプラットフォームからデータをクロールします。
キーワードとIDベース検索
キーワードまたは特定のIDを使用して投稿とコメントを検索できます。
データベースオプション
データストレージにSQLiteとMySQLをサポートします。
依存関係管理
`uv`を使用して、一貫したPython依存関係管理を行います。
ブラウザ自動化
ブラウザインタラクションにPlaywrightを採用しています。
設定可能
`config/base_config.py`でカスタマイズ可能なオプションを提供します。
404 の使い方
Python 3.11とNode.js(バージョン>= 16.0.0)をインストールします。uv syncを使用してPythonの依存関係を管理します。Playwrightブラウザドライバをインストールします:playwright install。config/base_config.pyで設定を構成します(例:コメント抽出を有効にする)。python main.py --platform --lt qrcode --type searchのようなコマンドを使用してクローラーを実行します。
404 の利用シーン
ソーシャルメディアモニタリング
特定のキーワードやトピックに関連するコンテンツを追跡および分析します。
コンテンツ集約
研究や分析のために、複数のプラットフォームから投稿とコメントを収集します。
データ分析
センチメント分析、トレンド特定、およびその他の分析目的のためにデータを収集します。
404 が役立つ人
研究者
研究プロジェクトのためにソーシャルメディアデータを収集および分析するため。
データアナリスト
ビジネスインテリジェンスのためにソーシャルメディアデータを収集および処理するため。
開発者
特定のデータ抽出ニーズに合わせてクローラーを使用およびカスタマイズするため。
404 の料金プラン
MediaCrawlerはオープンソースプロジェクトであり、無料で利用できます。