Magika
Detecção de arquivos via IA
Grátis
Plataformas suportadas
web
Tags de ferramenta
O que é Magika
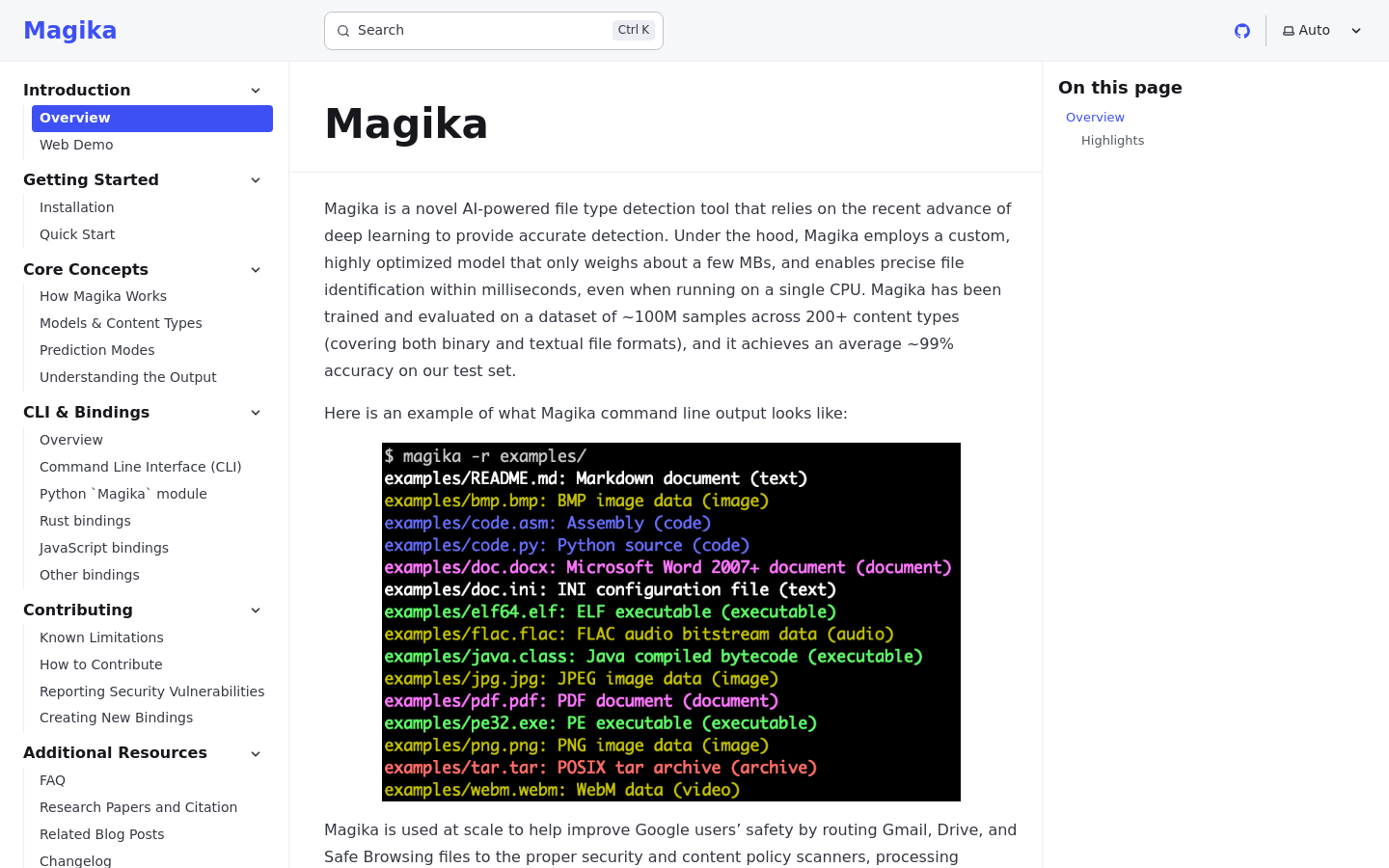
Magika é uma ferramenta de identificação de tipos de arquivo de alto desempenho desenvolvida pelo Google, utilizando um modelo de deep learning personalizado para classificar arquivos com extrema precisão. Diferente de ferramentas tradicionais como 'libmagic', que dependem de correspondência rígida de padrões de bytes, o Magika usa uma rede neural leve para analisar o conteúdo. Essa abordagem reduz significativamente as taxas de classificação incorreta para formatos complexos e arquivos de código. É projetado para ambientes de alto throughput, oferecendo uma CLI e API baseadas em Python que se integram perfeitamente a pipelines de segurança, sistemas de gerenciamento de conteúdo e fluxos de trabalho de processamento de dados onde a identificação precisa é crítica.
Principais recursos do Magika
Classificação por Deep Learning
O Magika utiliza um modelo de rede neural altamente otimizado para identificar tipos de arquivo com base em padrões de conteúdo, em vez de apenas magic numbers. Isso permite distinguir entre formatos similares—como diferentes versões de JavaScript ou arquivos de configuração—que ferramentas heurísticas tradicionais frequentemente identificam incorretamente, resultando em precisão superior para conjuntos de arquivos complexos.
Inferência de Alto Desempenho
O modelo é arquitetado para velocidade, capaz de processar milhares de arquivos por segundo em hardware padrão. Ao utilizar uma arquitetura compacta, minimiza o uso de CPU, tornando-o adequado para integração em servidores web de alto tráfego ou pipelines de ingestão de dados em larga escala onde a latência é uma preocupação principal.
Amplo Suporte a Formatos
O Magika suporta mais de 100 tipos de arquivo distintos, desde formatos de mídia comuns até linguagens de programação obscuras e estruturas binárias. O modelo é treinado em um dataset vasto e diversificado, garantindo robustez contra variações em cabeçalhos de arquivo e técnicas de ofuscação frequentemente encontradas em pesquisas de segurança.
Integração CLI Fluida
Projetada para engenheiros de DevOps e segurança, a CLI suporta piping padrão estilo Unix e varredura recursiva de diretórios. Fornece saída estruturada (JSON/JSONL), permitindo que usuários enviem resultados diretamente para outras ferramentas de segurança como SIEMs, plataformas de inteligência de ameaças ou sandboxes de análise de malware.
Baixo Consumo de Memória
Apesar do poder do deep learning, o modelo é otimizado para consumo mínimo de memória. Evita as dependências pesadas de frameworks maiores, permitindo a execução em ambientes com recursos limitados, como containers Docker ou funções serverless, sem exigir alocação significativa de RAM.
Como usar o Magika
Instale o pacote via pip usando 'pip install magika'.,Execute a ferramenta CLI em um único arquivo com 'magika path/to/file'., Processe diretórios inteiros recursivamente usando 'magika -r path/to/directory'., Integre em scripts Python importando a classe Magika e chamando 'm.identify_bytes(data)'., Exiba resultados em formato JSON para consumo automatizado em pipelines usando a flag '--json'.
Casos de uso do Magika
Pipelines de Análise de Malware
Pesquisadores de segurança usam o Magika para pré-filtrar fluxos de arquivos. Ao identificar com precisão os tipos de arquivo antes de enviá-los a ambientes de sandbox caros, as equipes economizam recursos computacionais e garantem que arquivos maliciosos sejam roteados corretamente para o motor de análise apropriado.
Filtragem de Upload de Conteúdo
Desenvolvedores web implementam o Magika em serviços de upload para impedir que usuários contornem filtros de segurança renomeando arquivos maliciosos. Ele garante que o conteúdo do arquivo corresponda ao tipo MIME esperado, mitigando riscos associados a uploads arbitrários.
Classificação de Data Lakes
Engenheiros de dados usam o Magika para escanear e categorizar data lakes massivos e não estruturados. Ao identificar tipos de arquivo em escala, eles podem automatizar a indexação de dados e garantir que processos ETL downstream processem apenas formatos válidos e esperados.
Quem se beneficia do Magika
Engenheiros de Segurança
Precisam identificar tipos de arquivo com precisão para detectar payloads maliciosos e aplicar políticas de segurança. O Magika fornece a precisão necessária para reduzir falsos positivos em sistemas automatizados de detecção de ameaças.
DevOps & SREs
Requerem ferramentas de alto desempenho e baixa latência para gerenciar pipelines de processamento de arquivos. A CLI e a API do Magika permitem fácil integração em fluxos de trabalho de CI/CD e infraestrutura automatizada.
Cientistas de Dados
Precisam limpar e classificar grandes datasets para machine learning. O Magika ajuda a automatizar a identificação de formatos de arquivo, garantindo a integridade dos dados antes do treinamento de modelos.
Preços do Magika
Projeto de código aberto lançado sob a licença Apache 2.0. Totalmente gratuito para usar, modificar e integrar em projetos comerciais ou privados.