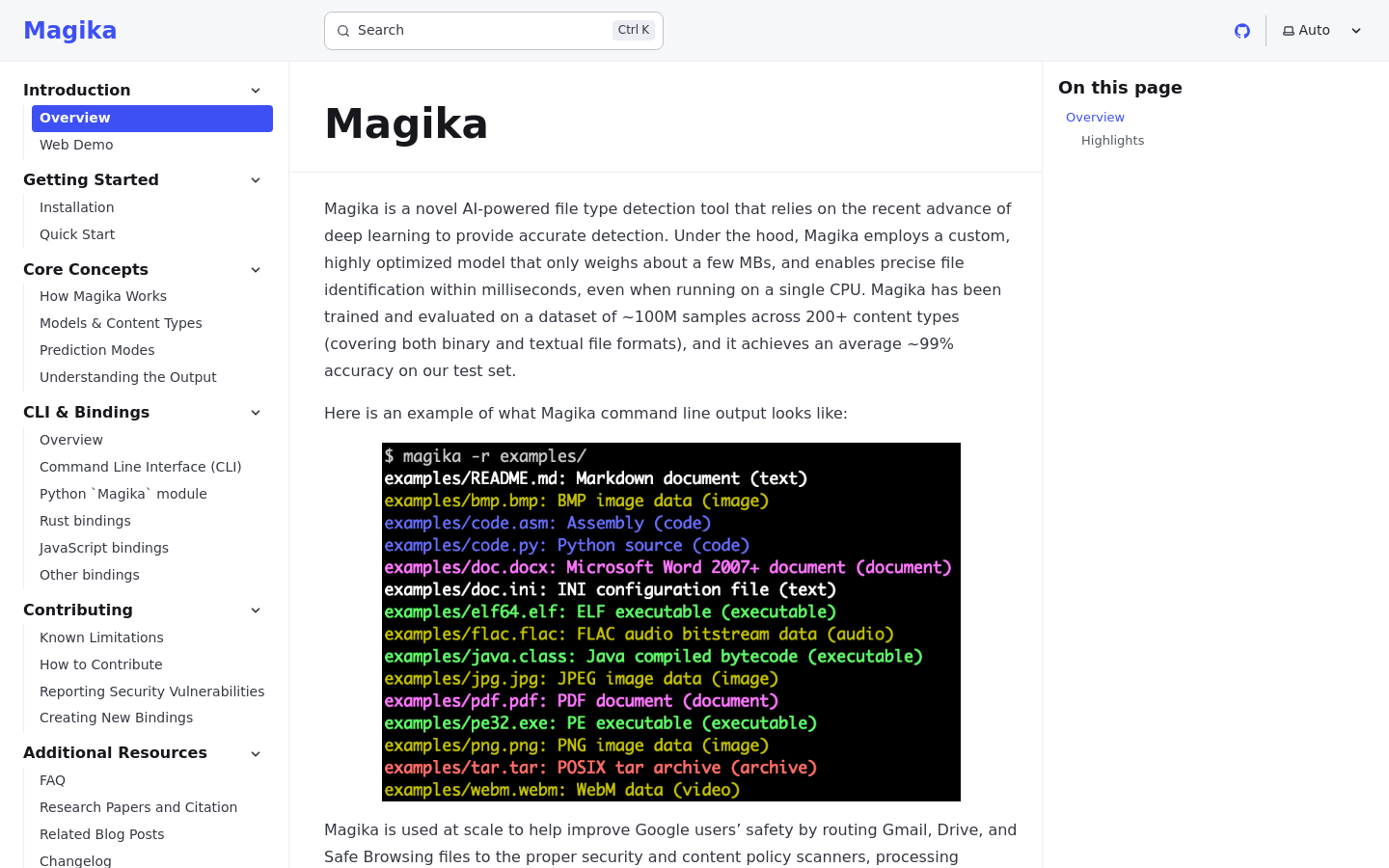
什麼是 Magika
Magika 是由 Google 開發的高效能檔案類型識別工具,利用自定義深度學習模型進行極高精度的檔案分類。與傳統依賴硬性、手動維護位元組模式匹配的 'libmagic' 工具不同,Magika 使用輕量級神經網路分析檔案內容。此方法顯著降低了複雜格式與程式碼檔案的誤判率。它專為高吞吐量環境設計,提供 Python CLI 與 API,可無縫整合至安全性管線、內容管理系統及資料處理工作流程中,在這些場景下,精確的檔案識別對於安全與路由至關重要。
Magika 的核心功能
深度學習分類
Magika 利用高度優化的神經網路模型,根據內容模式而非僅僅是 magic numbers 來識別檔案類型。這使其能夠區分相似的檔案格式(例如不同版本的 JavaScript 或設定檔),而傳統基於啟發式的工具往往會誤判,從而為複雜的檔案集提供更高的精確度。
高效能推論
該模型架構專為速度而設計,能在標準硬體上每秒處理數千個檔案。透過使用精簡的模型架構,它將 CPU 開銷降至最低,使其適合整合至高流量網頁伺服器或大規模資料擷取管線中,在這些環境下延遲是主要考量。
廣泛的格式支援
Magika 支援超過 100 種不同的檔案類型,從常見的媒體格式到冷門的程式語言與二進位結構皆包含在內。該模型在龐大且多樣化的資料集上進行訓練,確保其對安全研究中常見的檔案標頭變異與混淆技術具有強大的抵抗力。
無縫 CLI 整合
專為 DevOps 與安全工程師設計,CLI 支援標準 Unix 風格的管線傳輸與遞迴目錄掃描。它提供結構化輸出(JSON/JSONL),允許使用者將結果直接傳輸至其他安全工具,如 SIEM、威脅情報平台或自動化惡意軟體分析沙盒。
低記憶體佔用
儘管具備深度學習的強大功能,該模型仍針對最小化記憶體消耗進行了優化。它避免了大型框架的沉重依賴,使其能夠在 Docker 容器或無伺服器函式等資源受限的環境中執行,而無需分配大量的 RAM。
如何使用 Magika
透過 pip 安裝套件:'pip install magika'。使用 CLI 工具處理單一檔案:'magika path/to/file'。遞迴處理整個目錄:'magika -r path/to/directory'。匯入 Magika 類別並呼叫 'm.identify_bytes(data)' 以整合至 Python 指令碼。使用 '--json' 旗標輸出 JSON 格式結果,以便自動化管線使用。
Magika 的使用情境
惡意軟體分析管線
安全研究人員使用 Magika 預先篩選傳入的檔案串流。透過在將檔案傳遞至昂貴的沙盒環境前準確識別檔案類型,團隊可節省運算資源,並確保惡意檔案被正確路由至適當的分析引擎。
內容上傳過濾
網頁開發人員在檔案上傳服務中實作 Magika,以防止使用者透過重新命名惡意檔案來繞過安全過濾器。它確保檔案內容與預期的 MIME 類型相符,有效降低與任意檔案上傳相關的風險。
資料湖分類
資料工程師使用 Magika 掃描並分類龐大的非結構化資料湖。透過大規模識別檔案類型,他們可以自動化資料索引,並確保下游的 ETL 流程僅擷取有效且預期的檔案格式。
誰適合使用 Magika
安全工程師
需要準確識別檔案類型以偵測惡意負載並執行安全政策。Magika 提供了減少自動化威脅偵測系統中誤報所需的精確度。
DevOps 與 SRE
需要高效能、低延遲的工具來管理檔案處理管線。Magika 的 CLI 與 API 允許輕鬆整合至 CI/CD 工作流程與自動化基礎架構中。
資料科學家
需要清理並分類大型資料集以進行機器學習。Magika 有助於自動化識別檔案格式,確保在訓練模型前資料的完整性。
Magika 的價格方案
採用 Apache License 2.0 授權的開源專案。完全免費,可用於修改並整合至商業或私人專案中。