Apache DolphinScheduler
分散式資料工作流調度平台
免費
支援平台
web
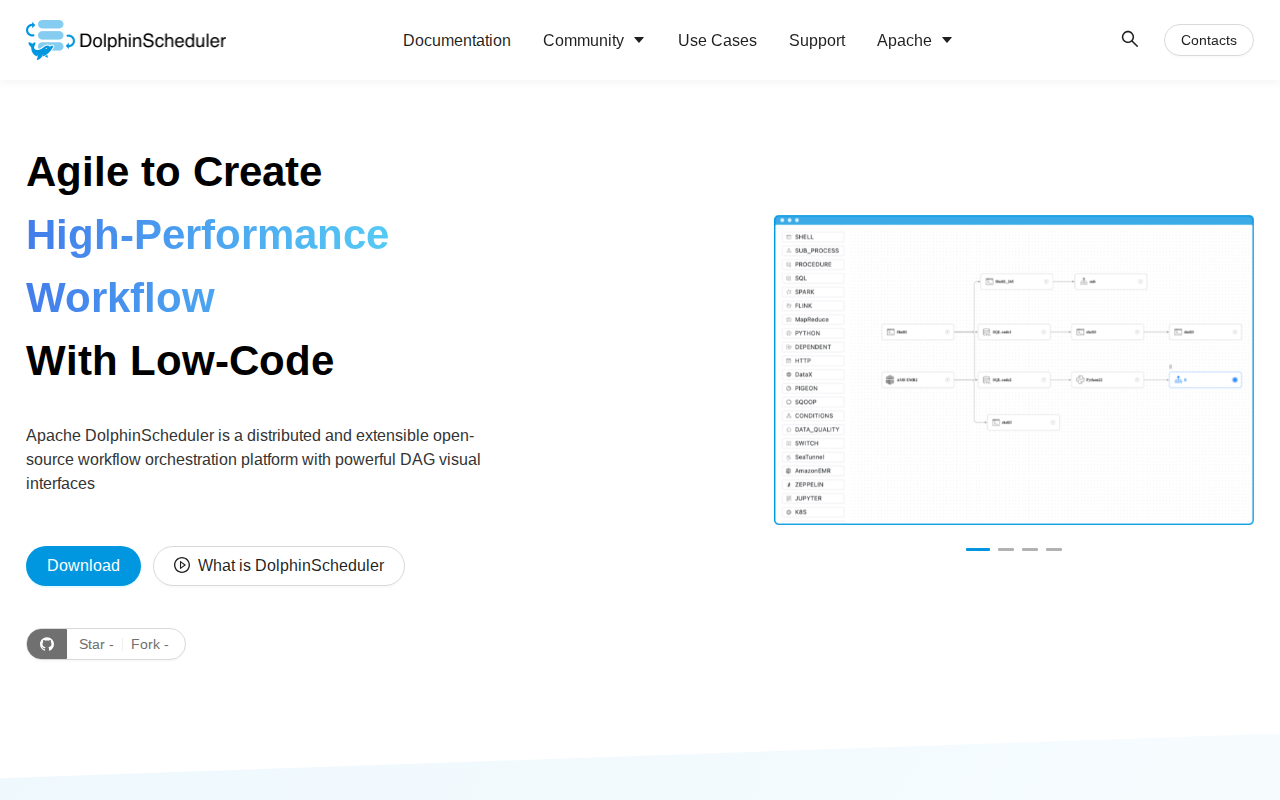
什麼是 Apache DolphinScheduler
Apache DolphinScheduler 是一個分散式、雲原生工作流調度平台,專為高效能資料管線管理而設計。與 Airflow 等傳統調度器不同,它具備視覺化 DAG(有向無環圖)編輯器及多 Master/多 Worker 架構,消除了單點故障。它支援複雜任務依賴、多租戶及高可用性,非常適合大型資料工程團隊。透過將調度器與執行引擎解耦,它為異質環境中數千個並發資料任務提供了強大的容錯能力與即時監控。
Apache DolphinScheduler 的核心功能
視覺化 DAG 工作流設計
直觀的拖放介面讓工程師無需編寫調度邏輯代碼即可構建複雜的資料管線。透過視覺化映射任務依賴,使用者可輕鬆管理分支、並行執行與條件邏輯。這減少了管線維護時間,並使工作流結構對非技術利害關係人透明,相較於純代碼配置工具,顯著降低了入門門檻。
多 Master/多 Worker 架構
DolphinScheduler 採用去中心化架構,多個 Master 與 Worker 節點在集群中運作。此設計確保了高可用性;若一個 Master 節點故障,其他節點會自動接管工作負載。相較於單調度器系統,這提供了卓越的可擴展性,使平台能處理數萬個並發任務而不降低效能或停機,這對企業級資料基礎設施至關重要。
強大的多租戶支援
平台透過多租戶提供嚴格的資源隔離,允許不同部門或團隊安全地共享同一集群。透過將任務映射至特定的 Linux 使用者與資源隊列,DolphinScheduler 確保一個團隊的資源密集型作業不會拖垮其他團隊。這對於大型組織至關重要,因為資料工程團隊必須在共享基礎設施成本與各業務單位的嚴格效能 SLA 之間取得平衡。
廣泛的任務類型支援
開箱即用支援多種任務類型,包括 Shell、Python、Spark、Flink、MapReduce、DataX 及 SQL。這種多功能性使團隊能在單一平台內調度異質資料處理作業。透過為這些引擎提供標準化插件,簡化了多樣化大數據技術的整合,減少了對自定義膠水代碼的需求,並簡化了整體資料堆疊架構。
即時監控與警報
整合式監控提供對任務執行的細粒度可視性,包括 CPU/記憶體使用率與日誌。系統支援透過電子郵件、Slack、釘釘與微信進行自定義警報。當任務失敗或超過持續時間閾值時,會觸發自動警報,讓工程師能立即回應。這種主動監控降低了平均修復時間 (MTTR),並確保了生產環境中關鍵資料管線的可靠性。
如何使用 Apache DolphinScheduler
- 使用 Docker Compose 或透過官方 Helm chart 在 Kubernetes 上部署 DolphinScheduler 集群。,2. 存取連接埠 12345 的 Web UI,並在「安全」標籤頁中配置資料來源連接(如 MySQL、PostgreSQL、Hive)。,3. 建立專案並使用拖放式 DAG 編輯器定義任務節點,包括 Shell、Python、Spark、Flink 或 SQL 腳本。,4. 定義任務依賴關係與執行參數,例如重試策略、逾時限制及資源組分配。,5. 使用 Cron 表達式或基於事件的依賴關係設定調度觸發器,以自動化管線執行。,6. 透過「監控」儀表板即時監控任務狀態、日誌與資源利用率,確保管線健康。
Apache DolphinScheduler 的使用情境
ETL 管線自動化
資料工程師使用 DolphinScheduler 自動化日常 ETL 作業,從營運資料庫提取資料,使用 Spark 進行轉換,並載入至資料倉儲。它透過依賴管理與自動重試確保資料一致性。
大數據集群管理
平台團隊透過將作業調度卸載至 DolphinScheduler 來管理大規模 Flink 與 Spark 集群。它優化了集群內的資源分配,確保高優先級分析作業在尖峰時段獲得必要的運算能力。
跨平台工作流整合
擁有混合技術堆疊的組織使用它來彌合傳統 SQL 腳本與現代 Python 機器學習管線之間的差距,為分散的資料處理工具提供統一的控制平面。
誰適合使用 Apache DolphinScheduler
資料工程師
需要一種可靠、可擴展的方式來管理複雜的多階段資料管線。DolphinScheduler 提供了自動化重複任務並確保資料品質的調度能力。
平台架構師
需要高可用性、多租戶解決方案來管理跨多個業務單位的共享基礎設施,同時保持嚴格的資源隔離與安全性。
DevOps 工程師
專注於基礎設施穩定性與監控。他們受益於平台的去中心化架構與強大的警報功能,以維持關鍵資料服務的正常運行時間。
Apache DolphinScheduler 的價格方案
採用 Apache License 2.0 授權的開源軟體。完全免費使用、修改並部署於任何環境,無授權費用。





