Apache DolphinScheduler
Điều phối luồng dữ liệu phân tán
Miễn phí
Nền tảng được hỗ trợ
web
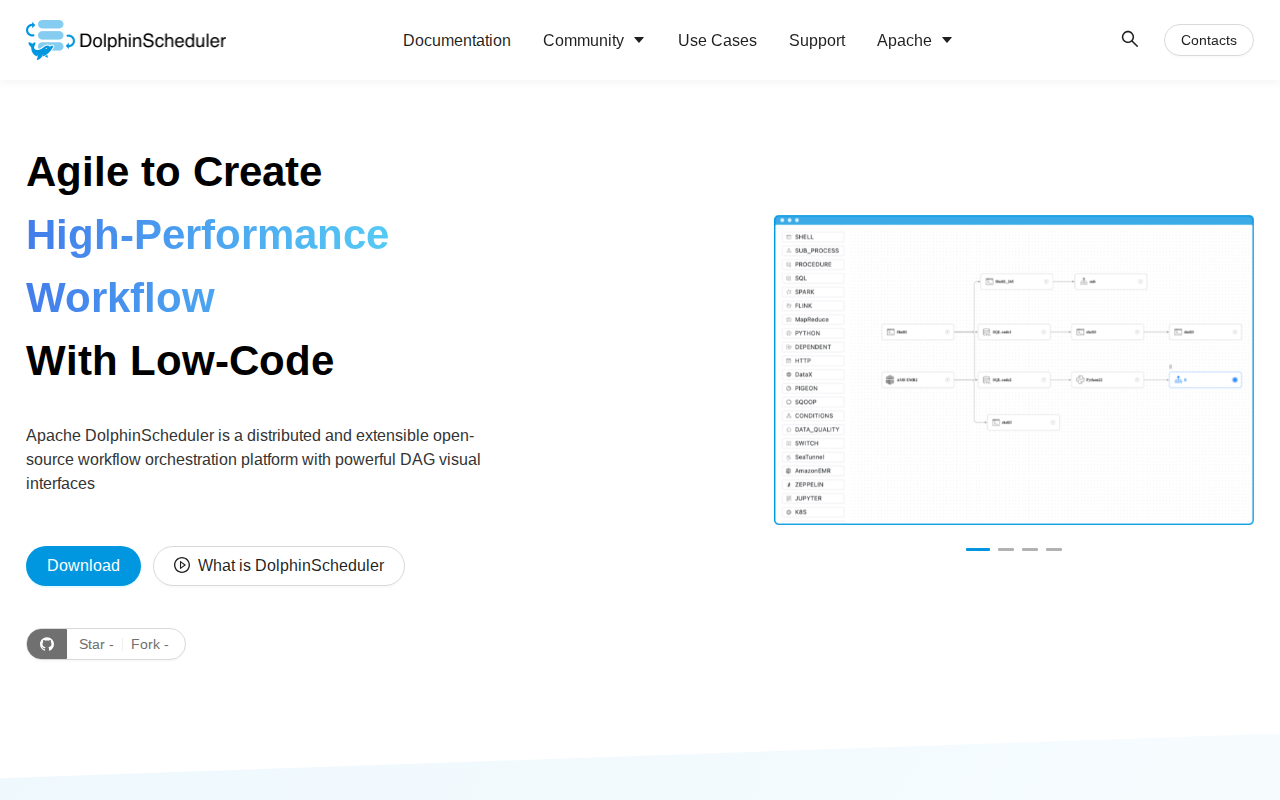
Apache DolphinScheduler là gì
Apache DolphinScheduler là nền tảng điều phối luồng công việc phân tán, cloud-native, được thiết kế để quản lý các pipeline dữ liệu hiệu năng cao. Khác với các trình lập lịch truyền thống như Airflow, nó sở hữu trình chỉnh sửa DAG (Đồ thị có hướng không chu trình) trực quan và kiến trúc multi-master/multi-worker giúp loại bỏ các điểm lỗi đơn lẻ. Nền tảng hỗ trợ các phụ thuộc tác vụ phức tạp, đa người dùng (multi-tenancy) và tính sẵn sàng cao, lý tưởng cho các đội ngũ kỹ thuật dữ liệu quy mô lớn. Bằng cách tách biệt trình lập lịch khỏi engine thực thi, nó cung cấp khả năng chịu lỗi mạnh mẽ và giám sát thời gian thực cho hàng ngàn tác vụ dữ liệu đồng thời trong các môi trường không đồng nhất.
Các tính năng chính của Apache DolphinScheduler
Thiết kế luồng công việc DAG trực quan
Giao diện kéo-thả trực quan cho phép các kỹ sư xây dựng các pipeline dữ liệu phức tạp mà không cần viết code cho logic điều phối. Bằng cách ánh xạ trực quan các phụ thuộc tác vụ, người dùng có thể dễ dàng quản lý phân nhánh, thực thi song song và logic điều kiện. Điều này giảm thời gian bảo trì pipeline và giúp cấu trúc luồng công việc trở nên minh bạch với các bên liên quan không chuyên về kỹ thuật, giảm đáng kể rào cản gia nhập so với các công cụ chỉ dùng cấu hình code.
Kiến trúc Multi-Master/Multi-Worker
DolphinScheduler sử dụng kiến trúc phi tập trung, nơi nhiều node master và worker vận hành trong một cụm. Thiết kế này đảm bảo tính sẵn sàng cao; nếu một node master gặp sự cố, các node khác sẽ tự động tiếp quản khối lượng công việc. Điều này mang lại khả năng mở rộng vượt trội so với các hệ thống lập lịch đơn lẻ, cho phép nền tảng xử lý hàng chục ngàn tác vụ đồng thời mà không bị suy giảm hiệu năng hoặc gián đoạn, yếu tố then chốt cho hạ tầng dữ liệu cấp doanh nghiệp.
Hỗ trợ Multi-Tenancy mạnh mẽ
Nền tảng cung cấp sự cô lập tài nguyên nghiêm ngặt thông qua tính năng đa người dùng, cho phép các phòng ban hoặc nhóm khác nhau chia sẻ cùng một cụm một cách an toàn. Bằng cách ánh xạ các tác vụ tới người dùng Linux và hàng đợi tài nguyên cụ thể, DolphinScheduler đảm bảo rằng công việc tiêu tốn nhiều tài nguyên của một nhóm không thể làm ảnh hưởng đến các nhóm khác. Điều này rất cần thiết cho các tổ chức lớn, nơi các đội ngũ kỹ thuật dữ liệu phải cân bằng chi phí hạ tầng dùng chung với các SLA hiệu năng nghiêm ngặt cho từng đơn vị kinh doanh.
Hỗ trợ đa dạng loại tác vụ
Hỗ trợ sẵn cho nhiều loại tác vụ, bao gồm Shell, Python, Spark, Flink, MapReduce, DataX và SQL. Sự linh hoạt này cho phép các nhóm điều phối các công việc xử lý dữ liệu không đồng nhất trong một nền tảng duy nhất. Bằng cách cung cấp các plugin tiêu chuẩn cho các engine này, nó đơn giản hóa việc tích hợp các công nghệ dữ liệu lớn đa dạng, giảm nhu cầu viết code tùy chỉnh và đơn giản hóa kiến trúc stack dữ liệu tổng thể.
Giám sát và cảnh báo thời gian thực
Tính năng giám sát tích hợp cung cấp khả năng hiển thị chi tiết về quá trình thực thi tác vụ, bao gồm mức sử dụng CPU/RAM và nhật ký. Hệ thống hỗ trợ cảnh báo tùy chỉnh qua email, Slack, DingTalk và WeChat. Khi một tác vụ thất bại hoặc vượt quá ngưỡng thời gian cho phép, các cảnh báo tự động sẽ được kích hoạt, cho phép các kỹ sư phản ứng ngay lập tức. Việc giám sát chủ động này giúp giảm thời gian trung bình để phục hồi (MTTR) và đảm bảo độ tin cậy của các pipeline dữ liệu quan trọng trong môi trường sản xuất.
Cách sử dụng Apache DolphinScheduler
- Triển khai cụm DolphinScheduler bằng Docker Compose hoặc Kubernetes thông qua Helm chart chính thức.,2. Truy cập giao diện web tại cổng 12345 và cấu hình kết nối nguồn dữ liệu (ví dụ: MySQL, PostgreSQL, Hive) trong tab 'Security'.,3. Tạo dự án và sử dụng trình chỉnh sửa DAG kéo-thả để định nghĩa các nút tác vụ, bao gồm các script Shell, Python, Spark, Flink hoặc SQL.,4. Xác định các phụ thuộc tác vụ và tham số thực thi, chẳng hạn như chính sách thử lại, giới hạn thời gian chờ và phân bổ nhóm tài nguyên.,5. Thiết lập các trình kích hoạt lịch trình bằng biểu thức Cron hoặc các phụ thuộc dựa trên sự kiện để tự động hóa việc thực thi pipeline.,6. Giám sát trạng thái tác vụ, nhật ký và mức sử dụng tài nguyên theo thời gian thực qua bảng điều khiển 'Monitor' để đảm bảo tính ổn định của pipeline.
Các trường hợp sử dụng của Apache DolphinScheduler
Tự động hóa ETL Pipeline
Các kỹ sư dữ liệu sử dụng DolphinScheduler để tự động hóa các công việc ETL hàng ngày nhằm trích xuất dữ liệu từ các cơ sở dữ liệu vận hành, chuyển đổi bằng Spark và tải vào kho dữ liệu. Nó đảm bảo tính nhất quán của dữ liệu thông qua quản lý phụ thuộc và tự động thử lại.
Quản lý cụm dữ liệu lớn
Các đội ngũ nền tảng quản lý các cụm Flink và Spark khổng lồ bằng cách chuyển giao việc lập lịch công việc cho DolphinScheduler. Nó tối ưu hóa việc phân bổ tài nguyên trên toàn cụm, đảm bảo các công việc phân tích ưu tiên cao nhận được sức mạnh tính toán cần thiết trong giờ cao điểm.
Tích hợp luồng công việc đa nền tảng
Các tổ chức sử dụng stack lai dùng nó để thu hẹp khoảng cách giữa các script SQL cũ và các pipeline học máy dựa trên Python hiện đại, cung cấp một mặt phẳng điều khiển thống nhất cho các công cụ xử lý dữ liệu khác biệt.
Ai sẽ được lợi từ Apache DolphinScheduler
Kỹ sư dữ liệu
Cần một cách đáng tin cậy và có khả năng mở rộng để quản lý các pipeline dữ liệu đa giai đoạn phức tạp. DolphinScheduler cung cấp sức mạnh điều phối để tự động hóa các tác vụ lặp đi lặp lại và đảm bảo chất lượng dữ liệu.
Kiến trúc sư nền tảng
Yêu cầu một giải pháp sẵn sàng cao, đa người dùng để quản lý hạ tầng dùng chung giữa nhiều đơn vị kinh doanh trong khi vẫn duy trì sự cô lập tài nguyên và bảo mật nghiêm ngặt.
Kỹ sư DevOps
Tập trung vào sự ổn định và giám sát hạ tầng. Họ được hưởng lợi từ kiến trúc phi tập trung và khả năng cảnh báo mạnh mẽ của nền tảng để duy trì thời gian hoạt động cho các dịch vụ dữ liệu quan trọng.
Giá của Apache DolphinScheduler
Phần mềm mã nguồn mở được cấp phép theo Apache License 2.0. Hoàn toàn miễn phí để sử dụng, sửa đổi và triển khai trong bất kỳ môi trường nào mà không mất phí bản quyền.





