什么是 Magika
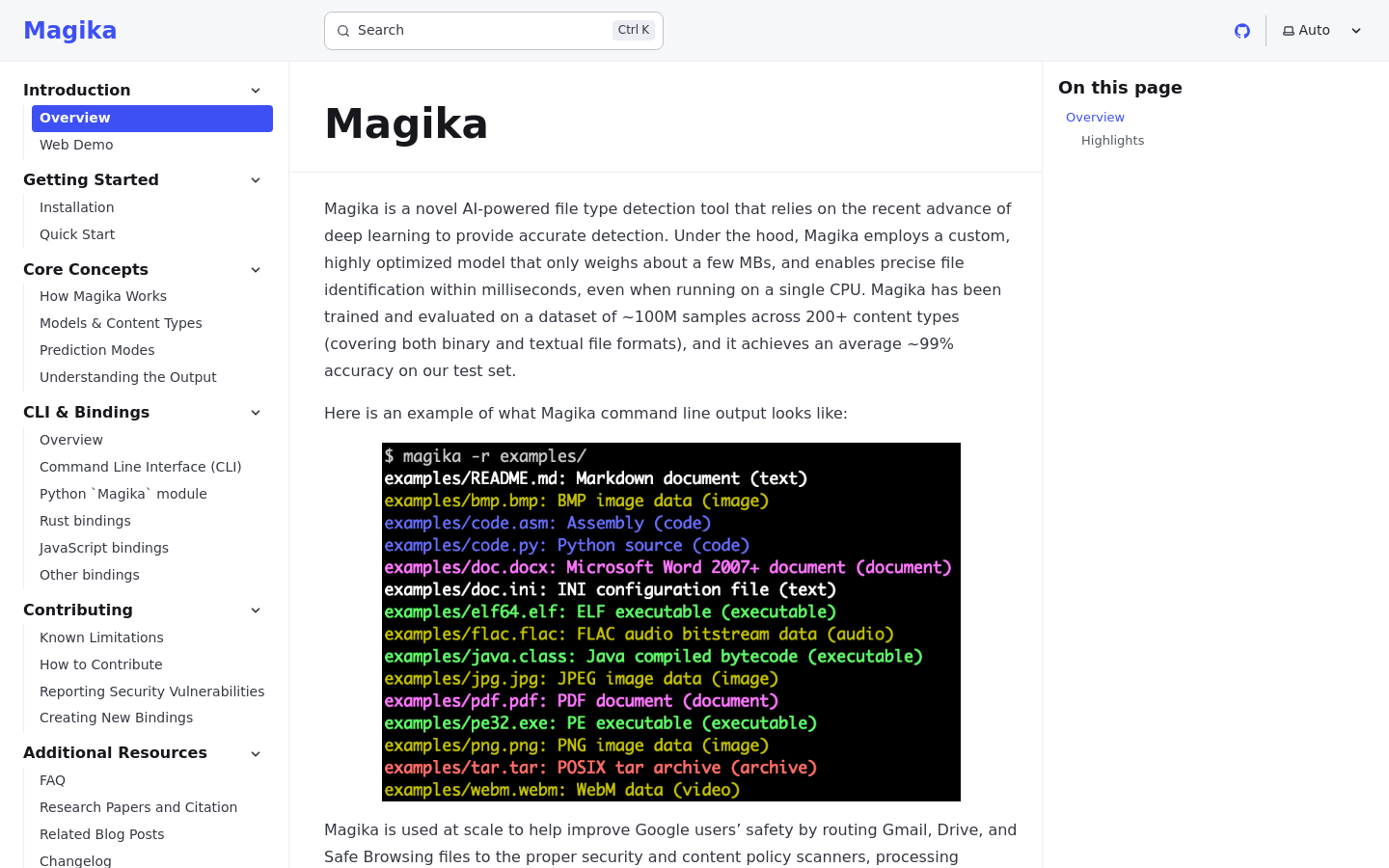
Magika 是由 Google 开发的高性能文件类型识别工具,利用定制的深度学习模型实现极高精度的文件分类。与依赖僵化、手动维护字节模式匹配的传统工具(如 libmagic)不同,Magika 使用轻量级神经网络分析文件内容。这种方法显著降低了复杂格式和代码文件的误分类率。它专为高吞吐量环境设计,提供 Python CLI 和 API,可无缝集成到安全管道、内容管理系统和数据处理工作流中,在这些场景下,精确的文件识别对于安全和路由至关重要。
Magika 的核心功能
深度学习分类
Magika 利用高度优化的神经网络模型,基于内容模式而非仅仅是魔数(magic numbers)来识别文件类型。这使其能够区分相似的文件格式(如不同版本的 JavaScript 或配置文件),而传统启发式工具往往会误判,从而显著提高了复杂文件集的识别精度。
高性能推理
该模型架构专为速度而设计,在标准硬件上每秒可处理数千个文件。通过采用紧凑的模型架构,它最大限度地减少了 CPU 开销,使其非常适合集成到高流量 Web 服务器或大规模数据摄取管道中,在这些场景下延迟是首要考虑因素。
广泛的格式支持
Magika 支持超过 100 种不同的文件类型,涵盖从常见媒体格式到晦涩的编程语言和二进制结构。该模型在庞大且多样化的数据集上进行训练,确保其在面对安全研究中常见的各种文件头变体和混淆技术时依然稳健。
无缝 CLI 集成
CLI 专为 DevOps 和安全工程师设计,支持标准的 Unix 风格管道和递归目录扫描。它提供结构化输出(JSON/JSONL),允许用户将结果直接传输到其他安全工具,如 SIEM、威胁情报平台或自动化恶意软件分析沙箱。
低内存占用
尽管具备深度学习能力,该模型仍针对最小化内存消耗进行了优化。它避免了大型框架的繁重依赖,使其能够在 Docker 容器或无服务器函数等资源受限的环境中运行,而无需分配大量 RAM。
如何使用 Magika
通过 pip 安装:'pip install magika'。使用 CLI 处理单个文件:'magika path/to/file'。递归处理整个目录:'magika -r path/to/directory'。在 Python 脚本中集成:导入 Magika 类并调用 'm.identify_bytes(data)'。使用 '--json' 标志输出 JSON 格式结果,以便自动化管道调用。
Magika 的使用场景
恶意软件分析管道
安全研究人员使用 Magika 对传入的文件流进行预过滤。通过在将文件传递给昂贵的沙箱环境之前准确识别文件类型,团队可以节省计算资源,并确保恶意文件被正确路由到相应的分析引擎。
内容上传过滤
Web 开发人员在文件上传服务中实施 Magika,以防止用户通过重命名恶意文件来绕过安全过滤器。它确保文件内容与预期的 MIME 类型匹配,从而有效降低与任意文件上传相关的风险。
数据湖分类
数据工程师使用 Magika 扫描和分类海量的非结构化数据湖。通过大规模识别文件类型,他们可以实现数据索引自动化,并确保下游 ETL 流程仅摄取有效且预期的文件格式。
谁适合使用 Magika
安全工程师
需要准确识别文件类型以检测恶意载荷并执行安全策略。Magika 提供了减少自动化威胁检测系统中误报所需的精度。
DevOps 与 SRE
需要高性能、低延迟的工具来管理文件处理管道。Magika 的 CLI 和 API 易于集成到 CI/CD 工作流和自动化基础设施中。
数据科学家
需要清理和分类大型数据集以进行机器学习。Magika 有助于自动化识别文件格式,确保在训练模型之前的数据完整性。
Magika 的价格方案
基于 Apache License 2.0 发布的开源项目。完全免费,可用于商业或私人项目,并支持修改和集成。