Apache DolphinScheduler
分布式数据工作流调度平台
免费
支持平台
web
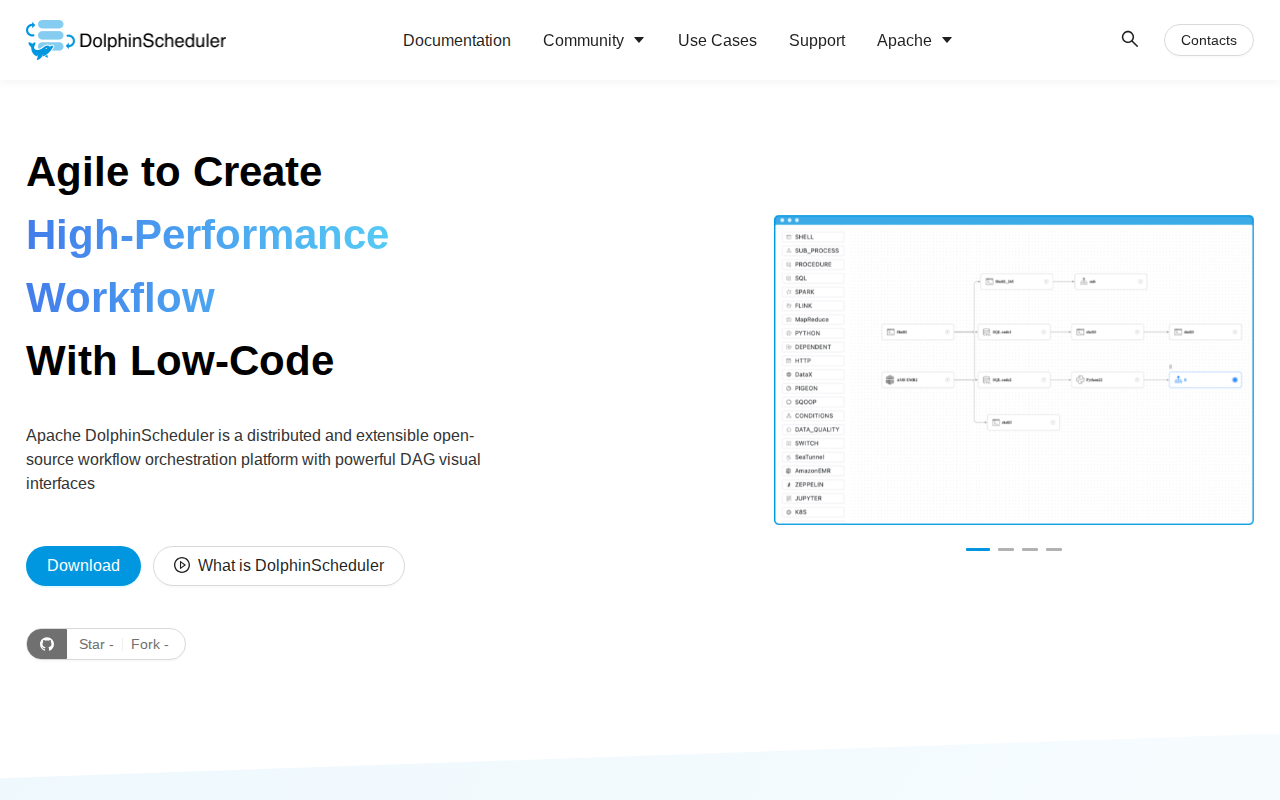
什么是 Apache DolphinScheduler
Apache DolphinScheduler 是一个分布式、云原生的工作流调度平台,专为高性能数据流水线管理而设计。与 Airflow 等传统调度器不同,它具备可视化 DAG(有向无环图)编辑器和多 Master/多 Worker 架构,消除了单点故障。它支持复杂的任务依赖、多租户和高可用性,非常适合大规模数据工程团队。通过将调度器与执行引擎解耦,它为异构环境下的数千个并发数据任务提供了强大的容错能力和实时监控。
Apache DolphinScheduler 的核心功能
可视化 DAG 工作流设计
直观的拖拽式界面允许工程师无需编写编排逻辑代码即可构建复杂的数据流水线。通过可视化映射任务依赖,用户可以轻松管理分支、并行执行和条件逻辑。这减少了流水线维护时间,并使工作流结构对非技术人员透明,相比纯代码配置工具显著降低了入门门槛。
多 Master/多 Worker 架构
DolphinScheduler 采用去中心化架构,集群中运行多个 Master 和 Worker 节点。该设计确保了高可用性;如果一个 Master 节点故障,其他节点会自动接管工作负载。相比单调度器系统,它提供了卓越的扩展性,能够处理数万个并发任务而不会出现性能下降或停机,这对企业级数据基础设施至关重要。
强大的多租户支持
该平台通过多租户提供严格的资源隔离,允许不同部门或团队安全地共享同一集群。通过将任务映射到特定的 Linux 用户和资源队列,DolphinScheduler 确保了一个团队的资源密集型作业不会影响其他团队。这对于大型组织至关重要,因为数据工程团队必须在共享基础设施成本与各业务单元严格的性能 SLA 之间取得平衡。
广泛的任务类型支持
开箱即用支持多种任务类型,包括 Shell、Python、Spark、Flink、MapReduce、DataX 和 SQL。这种多功能性允许团队在单一平台内编排异构数据处理作业。通过为这些引擎提供标准化插件,它简化了各种大数据技术的集成,减少了对自定义胶水代码的需求,并简化了整体数据栈架构。
实时监控与告警
集成监控提供了对任务执行的细粒度可见性,包括 CPU/内存使用情况和日志。系统支持通过电子邮件、Slack、钉钉和微信进行自定义告警。当任务失败或超过持续时间阈值时,会自动触发告警,使工程师能够立即响应。这种主动监控缩短了平均恢复时间 (MTTR),并确保了生产环境中关键数据流水线的可靠性。
如何使用 Apache DolphinScheduler
- 使用 Docker Compose 或通过官方 Helm chart 在 Kubernetes 上部署 DolphinScheduler 集群。,2. 访问 12345 端口的 Web UI,并在“安全”选项卡中配置数据源连接(如 MySQL、PostgreSQL、Hive)。,3. 创建项目并使用拖拽式 DAG 编辑器定义任务节点,包括 Shell、Python、Spark、Flink 或 SQL 脚本。,4. 定义任务依赖和执行参数,如重试策略、超时限制和资源组分配。,5. 使用 Cron 表达式或基于事件的依赖设置调度触发器,以实现流水线执行自动化。,6. 通过“监控”仪表板实时查看任务状态、日志和资源利用率,确保流水线健康运行。
Apache DolphinScheduler 的使用场景
ETL 流水线自动化
数据工程师使用 DolphinScheduler 自动化日常 ETL 作业,从操作数据库中提取数据,使用 Spark 进行转换,并将其加载到数据仓库中。它通过依赖管理和自动重试确保数据一致性。
大数据集群管理
平台团队通过将作业调度卸载到 DolphinScheduler 来管理大规模 Flink 和 Spark 集群。它优化了集群间的资源分配,确保高优先级分析作业在高峰时段获得必要的计算能力。
跨平台工作流集成
拥有混合技术栈的组织使用它来弥合传统 SQL 脚本与现代 Python 机器学习流水线之间的差距,为不同的数据处理工具提供统一的控制平面。
谁适合使用 Apache DolphinScheduler
数据工程师
需要一种可靠、可扩展的方式来管理复杂的多阶段数据流水线。DolphinScheduler 提供了编排能力,可自动化重复性任务并确保数据质量。
平台架构师
需要高可用、多租户的解决方案来管理跨多个业务单元的共享基础设施,同时保持严格的资源隔离和安全性。
DevOps 工程师
专注于基础设施的稳定性和监控。他们受益于平台的去中心化架构和强大的告警功能,以维持关键数据服务的正常运行时间。
Apache DolphinScheduler 的价格方案
基于 Apache License 2.0 协议的开源软件。完全免费使用、修改和部署在任何环境中,无任何许可费用。





