Apache DolphinScheduler
Distributed Data Workflow Orchestrator
Free
Support platforms
web
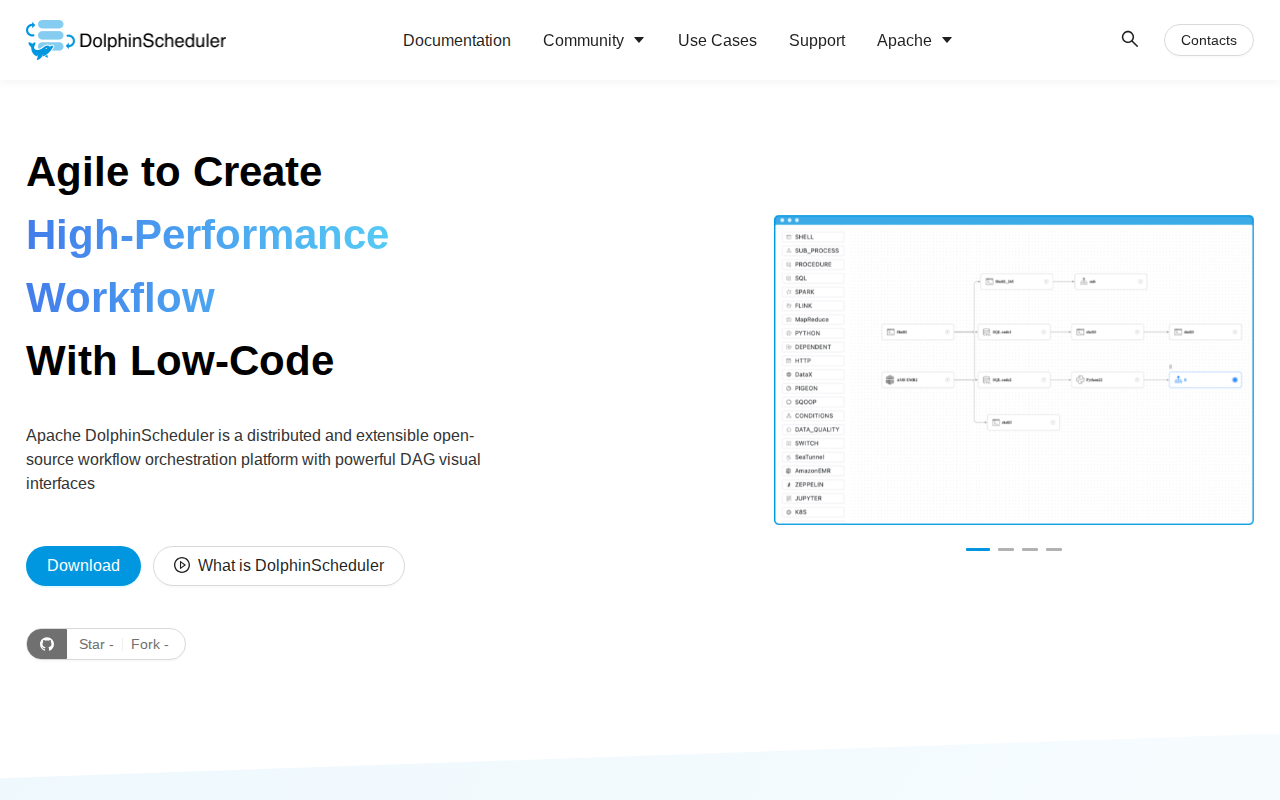
What is Apache DolphinScheduler
Apache DolphinScheduler is a distributed, cloud-native workflow orchestration platform designed for high-performance data pipeline management. Unlike traditional schedulers like Airflow, it features a visual DAG (Directed Acyclic Graph) editor and a multi-master/multi-worker architecture that eliminates single points of failure. It supports complex task dependencies, multi-tenancy, and high availability, making it ideal for large-scale data engineering teams. By decoupling the scheduler from the execution engine, it provides robust fault tolerance and real-time monitoring for thousands of concurrent data tasks across heterogeneous environments.
Apache DolphinScheduler 's Core features
Visual DAG Workflow Design
The intuitive drag-and-drop interface allows engineers to build complex data pipelines without writing code for orchestration logic. By visually mapping task dependencies, users can easily manage branching, parallel execution, and conditional logic. This reduces the time spent on pipeline maintenance and makes the workflow structure transparent to non-technical stakeholders, significantly lowering the barrier to entry compared to code-only configuration tools.
Multi-Master/Multi-Worker Architecture
DolphinScheduler employs a decentralized architecture where multiple master and worker nodes operate in a cluster. This design ensures high availability; if one master node fails, others automatically take over the workload. This provides superior scalability compared to single-scheduler systems, allowing the platform to handle tens of thousands of concurrent tasks without performance degradation or downtime, critical for enterprise-grade data infrastructure.
Robust Multi-Tenancy Support
The platform provides strict resource isolation through multi-tenancy, allowing different departments or teams to share the same cluster securely. By mapping tasks to specific Linux users and resource queues, DolphinScheduler ensures that one team's resource-heavy job cannot starve others. This is essential for large organizations where data engineering teams must balance shared infrastructure costs with strict performance SLAs for individual business units.
Extensive Task Type Support
Out-of-the-box support for a wide array of task types, including Shell, Python, Spark, Flink, MapReduce, DataX, and SQL. This versatility allows teams to orchestrate heterogeneous data processing jobs within a single platform. By providing standardized plugins for these engines, it simplifies the integration of diverse big data technologies, reducing the need for custom glue code and simplifying the overall data stack architecture.
Real-time Monitoring and Alerting
Integrated monitoring provides granular visibility into task execution, including CPU/memory usage and logs. The system supports customizable alerting via email, Slack, DingTalk, and WeChat. When a task fails or exceeds a duration threshold, automated alerts are triggered, allowing engineers to respond immediately. This proactive monitoring reduces Mean Time to Recovery (MTTR) and ensures the reliability of critical data pipelines in production environments.
How to use Apache DolphinScheduler
- Deploy the DolphinScheduler cluster using Docker Compose or Kubernetes via the official Helm chart.,2. Access the web UI on port 12345 and configure your data source connections (e.g., MySQL, PostgreSQL, Hive) in the 'Security' tab.,3. Create a project and use the drag-and-drop DAG editor to define task nodes, including Shell, Python, Spark, Flink, or SQL scripts.,4. Define task dependencies and execution parameters, such as retry policies, timeout limits, and resource group assignments.,5. Set up scheduling triggers using Cron expressions or event-based dependencies to automate pipeline execution.,6. Monitor real-time task status, logs, and resource utilization via the 'Monitor' dashboard to ensure pipeline health.
Use cases of Apache DolphinScheduler
ETL Pipeline Automation
Data engineers use DolphinScheduler to automate daily ETL jobs that extract data from operational databases, transform it using Spark, and load it into a data warehouse. It ensures data consistency through dependency management and automatic retries.
Big Data Cluster Management
Platform teams manage massive Flink and Spark clusters by offloading job scheduling to DolphinScheduler. It optimizes resource allocation across the cluster, ensuring that high-priority analytics jobs receive the necessary compute power during peak hours.
Cross-Platform Workflow Integration
Organizations with hybrid stacks use it to bridge the gap between legacy SQL scripts and modern Python-based machine learning pipelines, providing a unified control plane for disparate data processing tools.
Who benefits from Apache DolphinScheduler
Data Engineers
Need a reliable, scalable way to manage complex, multi-stage data pipelines. DolphinScheduler provides the orchestration power to automate repetitive tasks and ensure data quality.
Platform Architects
Require a high-availability, multi-tenant solution to manage shared infrastructure across multiple business units while maintaining strict resource isolation and security.
DevOps Engineers
Focus on infrastructure stability and monitoring. They benefit from the platform's decentralized architecture and robust alerting capabilities to maintain uptime for critical data services.
Pricing of Apache DolphinScheduler
Open-source software licensed under the Apache License 2.0. Completely free to use, modify, and deploy in any environment without licensing fees.





