Agenta
LLM App Prompt Management & Eval
Freemium
Support platforms
web
What is Agenta
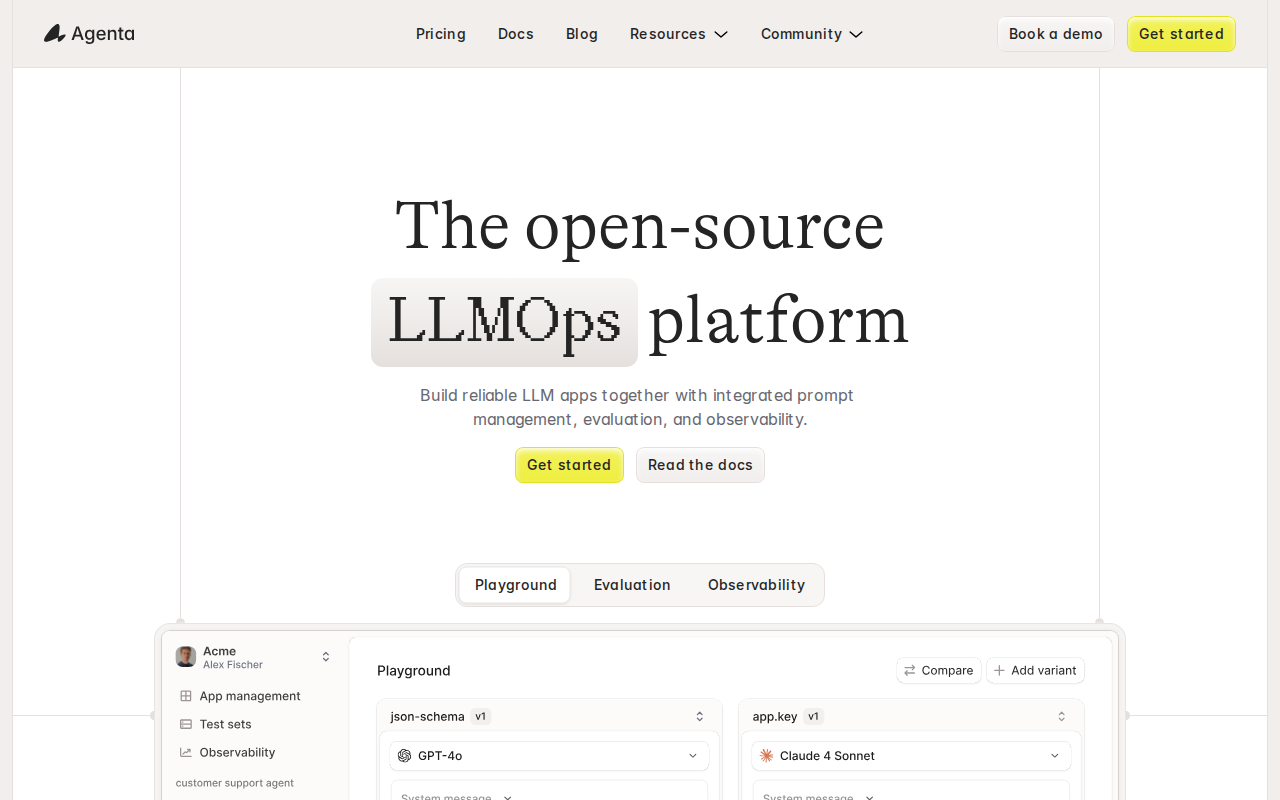
Agenta is a platform designed for managing, evaluating, and observing applications built with Large Language Models (LLMs). It provides a centralized hub for prompt management, allowing developers to version, test, and deploy prompts effectively. Agenta's core value lies in its ability to streamline the development lifecycle of LLM-powered applications by offering robust evaluation tools, enabling developers to compare the performance of different prompts and model configurations. Unlike generic LLM platforms, Agenta focuses specifically on the needs of developers building production-ready applications, offering features like automated evaluation metrics and detailed observability dashboards. The platform leverages a combination of prompt versioning, automated testing, and performance monitoring to ensure LLM applications are reliable and performant. This makes Agenta ideal for developers, AI engineers, and teams building and deploying LLM applications, helping them improve accuracy, reduce costs, and accelerate development cycles.
Agenta 's Core features
Prompt Versioning and Management
Allows developers to create, version, and manage prompts effectively. This feature enables easy tracking of prompt changes, facilitating A/B testing and rollback capabilities. It supports different prompt formats and allows for collaboration among team members, ensuring consistency and control over prompt evolution. This is crucial for maintaining application performance and adapting to model updates.
Automated Evaluation Metrics
Provides automated evaluation metrics to assess the performance of LLM prompts and models. This includes metrics such as accuracy, relevance, and fluency, providing quantitative insights into prompt effectiveness. The platform supports custom metric definitions and allows for the comparison of different prompt versions, enabling data-driven optimization of LLM applications. This feature reduces the need for manual evaluation.
A/B Testing for Prompts
Enables A/B testing of different prompts to determine which performs best. Users can define multiple prompt variations and compare their performance using various metrics. Agenta's platform automatically tracks and reports on the results, allowing developers to make informed decisions about which prompts to deploy. This iterative approach helps optimize LLM application performance.
Observability Dashboards
Offers detailed observability dashboards to monitor the performance of LLM applications in production. These dashboards provide real-time insights into key metrics such as latency, error rates, and token usage. Developers can track the performance of different prompts and models, identify bottlenecks, and troubleshoot issues quickly. This feature ensures the reliability and scalability of LLM applications.
Integration with LLM Providers
Seamlessly integrates with various LLM providers, including OpenAI, Cohere, and others. This allows developers to easily connect their applications to different models and experiment with various configurations. Agenta handles the complexities of API interactions, making it easier to switch between models and providers. This flexibility is essential for staying current with the rapidly evolving LLM landscape.
Collaboration and Team Management
Supports collaboration among team members, allowing multiple users to work on the same projects. Features include role-based access control, version control, and shared dashboards. This facilitates efficient teamwork and ensures that all team members have access to the necessary information and tools. This is particularly useful for larger development teams.
How to use Agenta
- Sign up for an Agenta account at the Agenta website.,2. Create a new project within the Agenta platform to organize your LLM application.,3. Integrate the Agenta SDK into your application code to enable prompt management and evaluation.,4. Define and version your prompts within the Agenta interface, experimenting with different variations.,5. Set up evaluation metrics and test cases to assess the performance of your prompts and LLM models.,6. Monitor the performance of your LLM application using Agenta's observability dashboards, tracking key metrics and identifying areas for improvement.
Use cases of Agenta
Optimizing Chatbot Responses
A customer support team uses Agenta to A/B test different prompts for their chatbot. They compare the performance of various prompts in terms of accuracy and customer satisfaction, ultimately improving the chatbot's ability to answer customer queries effectively and reduce support ticket volume.
Improving Content Generation
A marketing team uses Agenta to evaluate different prompts for generating marketing copy. They test various prompts, measuring the quality and relevance of the generated content. This helps them identify the most effective prompts for creating compelling marketing materials, leading to higher engagement rates.
Enhancing Code Generation
A software development team uses Agenta to manage and evaluate prompts for code generation tools. They compare the performance of different prompts in terms of code quality and efficiency. This helps them optimize the prompts, leading to faster development cycles and improved code quality.
Monitoring LLM Application Performance
A data science team uses Agenta's observability dashboards to monitor the performance of their LLM-powered application in production. They track key metrics such as latency and error rates, identifying and resolving performance bottlenecks. This ensures the application remains reliable and responsive.
Who benefits from Agenta
AI Engineers
AI engineers benefit from Agenta's ability to streamline the development and deployment of LLM applications. They can use the platform to manage prompts, evaluate performance, and monitor applications in production, improving efficiency and accuracy.
Software Developers
Software developers can leverage Agenta to integrate LLMs into their applications more effectively. The platform provides tools for prompt management, testing, and monitoring, enabling developers to build and maintain robust LLM-powered features.
Data Scientists
Data scientists can use Agenta to experiment with different LLM models and prompts. The platform provides tools for evaluating performance and comparing results, helping data scientists optimize their models and improve application outcomes.
Product Managers
Product managers can use Agenta to track the performance of LLM-powered features and make data-driven decisions. The platform provides insights into key metrics, helping product managers understand user behavior and improve product performance.
Pricing of Agenta
Pricing not explicitly stated on the landing page. Likely a freemium model with a free tier and paid plans for increased usage and features.